
The Most Common Machine Learning Terms, Explained

Here's What We've Covered!
Have you used the Gaana app or Saavn or Spotify? I am sure, Yes.
Well, once you play a romantic song, the app you are using automatically plays the song of the same genre to give a soothing effect.
That is the magic of Machine Learning. The machine automatically learns and understands about what song should be played next.
So, what is “machine learning”? According to McKinsey, it can be defined as an algorithm that doesn’t rely on rules-based programming but rather operates on continuous learning from available data. Another definition by Carnegie Mellon University states that machine learning techniques can be used to build computer systems that can automatically improve with experience. To put it simply, machine learning helps in improving the accuracy of a system over a period of time by leveraging the ever-increasing data and feedback. In fact, machine learning complements the work of artificial intelligence due to which computers nowadays can “learn” for themselves to build new rules through practice and repetition.
Such advanced applications have made machine learning what it is today.


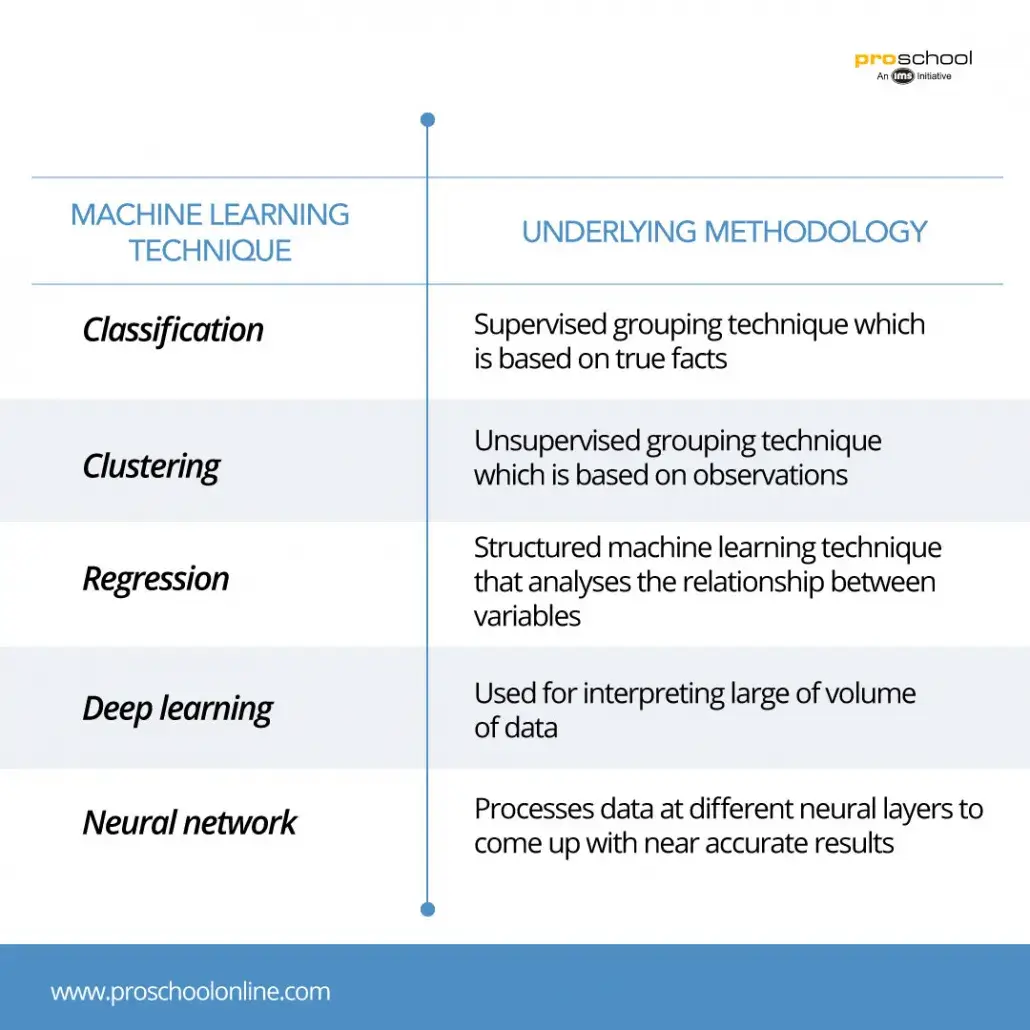
CLASSIFICATION
Classification is a type of supervised learning technique in which input data is arranged into different categories. In machine learning, there can be either binary classifiers that have only two possible outcomes (e.g., “Yes” or “No”) or multi-class classifiers (e.g., number of countries).
A decision tree is one of the prime examples of classification algorithms, where the laddering technique of the “if-then” framework is used to build precise classifications to narrow down the pool of possibilities over several repeated steps.
CLUSTERING
Clustering, unlike classification, is a type of unsupervised learning technique in which data is grouped based on features and attributes. This technique is usually used to categorize customer demographics and their purchasing behavior into distinguishable segments that are later used for product positioning. It also has many other applications that include analysis of housing quality & geographic locations, classification of information, etc.
One of the most common examples of clustering is K-means clustering, in which each cluster is represented by a variable “k” and has a defined centroid. After that each data point is assigned to a particular cluster one after the other and, in this way, we are able to pinpoint the centroid of the new clusters.
REGRESSION
Regression is a type of structured machine learning technique in which the inputs and outputs are labeled. Mostly used regression technique is the linear regression that provides outputs with continuous variables. Regressions also help in determining relationships and correlations among different data points. Regressions also find application in the prediction of the recovery of cognitive functions after a stroke or prediction of customer churn in a certain industry. Over a period of time, the efficiency and the speed of regression analysis has improved significantly.
For instance, a system identifies the image in a profile picture by pixels and relates it to a certain person. Machine learning then assigns that pixel arrangement to a particular name which eventually assists in facial recognition witnessed in case of Facebook photo tagging.
DEEP LEARNING

Deep learning is a machine learning technique in which the algorithm is built in such a way that it is able to mimic the functions of a human brain. Deep learning networks are used for interpreting big data (either unstructured or structured) and identifying patterns in them. The accuracy of the decision of a deep learning exercise is directly proportional to the amount of information that it can access and as such availability of more information results in better and accurate decisions.
Virtual assistants such as Alexa and Siri or chatbots associated with customer service at the different websites are the prime examples of deep learning. These applications are capable of receiving human requests, deciphering the language and then coming up with life-like responses.
NEURAL NETWORK
A neural network is an extension of the deep learning technique. In this process, sequential layers of neurons are created in order to further understand the collected data which can be used to provide more accurate analysis.
![]()
A neural network comprises several layers of nodes and each layer receives stimulus from a “trigger” data. The input/ trigger data is processed at each layer, each more advanced than the preceding one. After passing through numerous neural layers the data is finally recognized by the system. A neural network consists of three major layers: the input layer of data, a hidden layer that contains mathematical computations and the output layer.
For instance, when we search for airline ticket prices, the input layer collects different data points like origin airport, destination airport, and date of travel. Each of these data points would be routed through the hidden layer where it will be assigned a weightage and then finally the output layer would display the estimated airline ticket price.
CONCLUSION
The above-mentioned techniques are some of the most commonly used terms in the world of machine learning. It is important that you know about them because machine learning and artificial intelligence are likely to be most sought after skillset in the near future. What is more interesting is that there is a huge dearth of such qualified professionals. So, if you want to enjoy healthy professional growth in the future, then it is time you take the plunge into the ocean of machine learning.Read more: Impact of Data Science on Retail Industry

Dwij K
Resent Post
Follow Us For All Updates!


